PIL, often known as the Python Imaging Library, is a freely available library designed for manipulating images in the Python programming language. The software offers a diverse array of image processing functionalities and is compatible with several image file types. It is worth mentioning that starting from 2011, the original PIL project has ceased to be actively developed, and Pillow, a derivative of PIL, has taken its place as the new and improved version. Pillow is currently undergoing active development and is the preferred option for doing image processing tasks in the Python programming language.
Within this framework, we will explore several modules of the Python Imaging Library (PIL) using real-time illustrations.
Image Module
The image module has a class called "Image" that is used to represent the PIL (Python Imaging Library) picture. The module also offers many factory methods, such as routines for loading images from files and creating new images.
Opening an Image
PIL.Image.open(fp, mode = 'r', formats = None) : Image
Open and identifies the given image file.
This action is considered lazy; the function is able to identify the file, however, the file stays open and the actual picture data is not read from the file until you attempt to analyze the data or use the load() method.
Parameters
- fp - A string representing a filename, a pathlib object, or a file object. The file object must have the file.read, file.seek, and file.tell methods implemented, and it should be opened in binary mode. Additionally, the file object will automatically seek to the beginning before reading.
- mode - The mode parameter must be "r" if provided.
- formats - A list or tuple specifying the file formats to be used for loading. This might be used to limit the range of formats examined. Specify None as the input to test all formats that are currently supported. To get the list of possible formats, use the command python3 -m PIL or utilize the PIL.features module.pilinfo() function.
Returns - An Image object.
Example --
from PIL import Image
image = Image.open("grizzly_bear.jpg", mode = "r", formats = None)
image.show()
Image.show(title = None)
Displays this image. This method is mainly intended for debugging purposes. This method calls PIL.ImageShow.show() internally. You can use PIL.ImageShow.register() to override its default behavior. The image is first saved to a temporary file. By default, it will be in PNG format. On Unix, the image is then opened using the xdg-open, display, gm, eog or xv utility, depending on which one can be found. On macOS, the image is opened with the native Preview application. On Windows, the image is opened with the standard PNG display utility.
Bands
An image may include one or many bands of data. The Python Imaging Library enables the storage of many bands inside a single picture, as long as they possess identical size and depth. As an example, a PNG image might have separate 'R', 'G', 'B', and 'A' bands representing the red, green, blue, and alpha transparency values, respectively. Several processes are performed individually on each band, such as histograms. Each pixel may be conceptualized as having a single value for each band, which is typically beneficial.
Modes
The image mode is a string that specifies the pixel type and depth in the image. Every pixel utilizes the whole spectrum of the bit depth. A 1-bit pixel may only have two possible values, 0 or 1. An 8-bit pixel can have 256 possible values, ranging from 0 to 255. A 32-signed integer pixel can have values within the range of INT32, which is a signed 32-bit integer. A 32-bit floating point pixel can have values within the range of FLOAT32, which is a 32-bit floating point number. The present version has the following standard modes:
- 1 (1-bit pixels, black and white, stored with one pixel per byte)
- L (8-bit pixels, grayscale)
- P (8-bit pixels, mapped to any other mode using a color palette)
- RGB (3x8 bit pixels, true color)
- RGBA (3x8 bit pixels, true color with transparency mask)
- CMYK (4x8 bit pixels, color separation)
- YCbCr (3x8 bit pixels, color video format)
Image Attributes
Instance of the Image class have the following attributes:
Image.filename : str
The filename or location of the source file. The filename property is only present in images that are generated using the factory function open. If the input is a file-like object, the filename property is assigned an empty string value.
from PIL import Image
image = Image.open("Image.png")
filename = image.filename
filename
Image.format : str|None
The format in which the source file is stored. For images generated by the library itself (using a factory function or by executing a method on an existing image), this property is assigned a value of None.
image_format = image.format
image_format
Image.mode : str
Image mode. This is a string that indicates the pixel format used by the image. Common values are "1", "L", "RGB", or "CMYK".
image_mode = image.mode
image_mode
Image.size : tuple[int]
Pixel dimensions of the image. The dimensions are specified as a 2-tuple consisting of the width and height.
image_size = image.size
image_size
The image properties Image.width and Image.height may be used to get the pixel dimensions of the picture, namely its width and height.
Image.info : dict
An image dictionary including linked data. File handlers use this dictionary to transmit diverse non-image data extracted from the file. Refer to the documentation for comprehensive information on the different file handlers. The majority of methods do not take the dictionary into consideration while generating new pictures. This is because the keys in the dictionary are not standardized, making it impossible for a method to determine whether the operation has any impact on the dictionary. To retain the information for future use, save a reference to the dictionary called "info" that is returned by the open method.
image_dict = image.info
image_dict
Another image property is Image.is_animated, which returns a boolean value indicating whether an image is animated or not. Another useful attribute is Image.n_frames, which returns an integer value representing the number of frames in an animated image.
Resizing an Image
Image.resize(size, resample = None, box = None, reducing_gap = None) : Image
Returns a resized copy of the image.
Where size is the required size in pixels, as a 2-tuple (width, height). resample is an optional resampling filter. This can be one of Resampling.NEAREST, Resampling.BOX, Resampling.BILINEAR, Resampling.HAMMING, Resampling.BICUBIC or Resampling.LANCZOS. If the image has mode “1” or “P”, it is always set to Resampling.NEAREST. If the image mode specifies a number of bits, such as “I;16”, then the default filter is Resampling.NEAREST. Otherwise, the default filter is Resampling.BICUBIC.
box is also an optional 4-tuple of floats providing the source image region to be scaled. The values must be within (0, 0, width, height) rectangle. If omitted or None, the entire source is used.
reducing_gap apply optimization by resizing the image in two steps. First, reducing the image by integer times using reduce(). Second, resizing using regular resampling. The last step changes size no less than by reducing_gap times. reducing_gap may be None (no first step is performed) or should be greater than 1.0. The bigger reducing_gap, the closer the result to the fair resampling. The smaller reducing_gap, the faster resizing. With reducing_gap greater or equal to 3.0, the result is indistinguishable from fair resampling in most cases. The default value is None (no optimization).
from PIL import Imae
image = Image.open("Image.png")
image
The current size of the image is (605, 605).
resized_image = image.resize((224,224), resample = None, box = None, reducing_gap = None)
resized_image
The size of the resized_image is (224, 224).
Rotating an Image
Image.rotate(angle, resample = Resampling.NEAREST, expand = 0, center = None, translate = None, fillcolor = None)
Generates a copied version of the image that has been rotated. The function returns a copy of the image, rotated in a counterclockwise direction by the specified number of degrees around its center.
PARAMETERS
- angle – In degrees counterclockwise.
- resample – An optional resampling filter. This can be one of Resampling.NEAREST (use nearest neighbour), Resampling.BILINEAR (linear interpolation in a 2x2 environment), or Resampling.BICUBIC (cubic spline interpolation in a 4x4 environment). If omitted, or if the image has mode “1” or “P”, it is set to Resampling.NEAREST.
- expand – Optional expansion flag. If true, expands the output image to make it large enough to hold the entire rotated image. If false or omitted, make the output image the same size as the input image. Note that the expand flag assumes rotation around the center and no translation.
- center – Optional center of rotation (a 2-tuple). Origin is the upper left corner. Default is the center of the image.
- translate – An optional post-rotate translation (a 2-tuple).
- fillcolor – An optional color for area outside the rotated image.
rotated_image = image.roatate(45, resample = Image.Resampling.NEAREST, expand = 0, center = None, translate = None, fillcolor = 'black')
rotated_image
We can also provide negative angle value to rotate the image clockwise.
Saving an Image
Image.save(fp, format = None, **params) : None
Saves this image under the given filename. If no format is specified, the format to use is determined from the filename extension, if possible. Keyword options can be used to provide additional instructions to the writer. If a writer doesn’t recognize an option, it is silently ignored.
PARAMETERS
- fp – A filename (string), pathlib.Path object or file object.
- format – Optional format override. If omitted, the format to use is determined from the filename extension. If a file object was used instead of a filename, this parameter should always be used.
- params – Extra parameters to the image writer.
rotated_image.save("rotated.png")
Image-Filter Module
The Python Imaging Library (PIL) includes the ImageFilter module, which offers a collection of a predetermined image filters. These filters can be used to apply different effects to images, including blurring, sharpening, edge detection, and others. This module is a component of the PIL library and its successor, Pillow.
Blurring
Blurring is a frequent image processing method that decreases the degree of detail and enhances the edges in a picture. Blurring serves several objectives, including reducing noise, emphasizing certain characteristics, and producing artistic effects.
PIL.ImageFilter.BoxBlur(radius)
This function applies a blurring effect to the picture by assigning each pixel the average value of the pixels inside a square box that extends a certain number of pixels in each direction. Allows for the use of a floating-point radius of any magnitude. Utilizes an efficient algorithm that operates with a temporal complexity proportional to the size of the picture for every given radius value.
PARAMETERS
- radius – Size of the box in a direction. Either a sequence of two numbers for x and y, or a single number for both. Radius 0 does not blur, returns an identical image. Radius 1 takes 1 pixel in each direction, i.e. 9 pixels in total.
Code Example:
from PIL import Image
from PIL import ImageFilter
image = Image.open("drd.jpg")
image # original image without blur filter
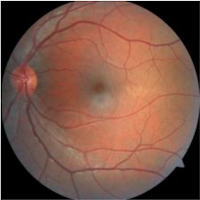 |
| Original Image |
blurred_image = image.filter(ImageFilter.BoxBlur(radius = 1))
blurred_image # blurred image
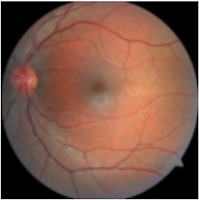 |
| Blurred Image |
PIL also provides another blurring filter GaussianBlur, which can be also applied to images to apply blurring effect on images.
PIL.ImageFilter.GaussianBlur(radius = 2)
Sharpening
A sharpening filter is an image filter that intensifies the edges and intricate features in a picture, making them more distinct and visually captivating. The main objective of sharpening is to enhance the clarity and sharpness of a picture. Multiple sharpening strategies exist, and a prevalent one involves using convolution processes with a designated kernel or filter.
In the field of image processing, a kernel refers to a compact matrix that is applied to the picture using convolution. This method allows for various operations such as blurring, sharpening, or detecting edges. The sharpening filter often employs a kernel that highlights the disparities in brightness among adjacent pixels, intensifying transitions and edges.
PIL.ImageFilter.Kernel(size, kernel, scale = None, offset = 0)
Create a convolution kernel. The present iteration only accommodates integer and floating-point kernels of dimensions 3x3 and 5x5. Currently, kernels may only be used on photos that are in the "L" and "RGB" formats.
PARAMETERS
- size – Kernel size, given as (width, height). In the current version, this must be (3,3) or (5,5).
- kernel – A sequence containing kernel weights. The kernel will be flipped vertically before being applied to the image.
- scale – Scale factor. If given, the result for each pixel is divided by this value. The default is the sum of the kernel weights.
- offset – Offset. If given, this value is added to the result, after it has been divided by the scale factor.
Code Example:
from PIL import Image
from PIL import ImageFilter
image = Image.open("drd.jpg")
image # original image without blur filter
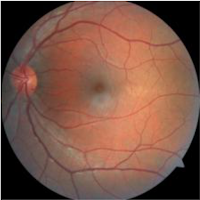 |
| Original Image |
# Define a kernal as a list of coefficients
kernel = [-1, -1, -1, -1, 9, -1, -1, -1, -1] # For a 3x3 kernel with a central weight of 9
sharpened_image = image.filter(ImageFilter.kernel((3,3), kernel, scale = 1, offset = 0))
sharpened_image
 |
| Sharpened Image |
PIL also support filter such as Unsharmask for image processing.
class PIL.ImageFilter.UnsharpMask(radius = 2, percent = 150, threshold = 3)
This is Unsharp mask filter.
PARAMETERS
- radius – Blur Radius
- percent – Unsharp strength, in percent
- threshold – Threshold controls the minimum brightness change that will be sharpened.
Rank Filter
A rank filter is an image filter that applies a pixel-wise operation using the pixel values in the surrounding area of each pixel. Rank filters differ from linear filters in that they take into account the order or rank of pixel values in the neighborhood, rather than using a weighted average of pixel values. The main concept is to substitute the center pixel with the pixel value that corresponds to a certain rank, such as the lowest, highest, or middle value, within the nearby area.
Min Filter
class PIL.ImageFilter.MinFilter(size = 3)
Creates a min filter, which picks the lowest pixel value in a window with the given size.
where, size - The kernel size, in pixels.
Code Example:
min_image = image.filter(ImageFilter.MinFilter(size = 3))
min_image
Median Filter
class PIL.ImageFilter.MedianFilter(size =3)
Creates a median filter, which picks the meadian pixel value in a window with the given size.
where, size - The kernel size, in pixels.
Code Example:
median_image = image.filter(ImageFilter.MedianFilter(size = 3)
median_image
Max Filter
class PIL.ImageFilter.MinFilter(size = 3)
Creates a max filter, which picks the largest pixel value in a window with the given size.
where, size - The kernel size, in pixels.
Code Example:
max_image = image.filter(ImageFilter.MaxFilter(size = 3)
max_image
Mode Filter
class PIL.ImageFilter.ModeFilter(size = 3)
Develop a mode filter. Determines the pixel value that appears most often inside a box of the specified dimensions. Pixel values that have a frequency of one or two are disregarded; if no pixel value has a frequency greater than two, the original pixel value is retained.
Code Example:
mode_image = image.filter(ImageFilter.ModeFilter(size = 3)
mode_image
 |
| Rank Filter |
That's it for Image Module and ImageFilter Module of PIL python library for Image handling and Image processing, I will write in more detail about ImageEnhance Module in another post.
Keep in touch and Good Luck!