
We all know that the cardiovascular diseases (CVDs), heart
disease, acknowledged as the most common cause of death during the preceding
several decades, is now recognized as the most lethal condition, not just in
India but throughout the globe. In humans, the heart is important. A small
error can result in tiredness issues or even death. One of the most significant
challenges confronting medical sector today is the prediction or forecasting of
heart illness. It is associated with numerous and intimidating factors and
components. An early diagnosis must be made using a prediction model that is
reliable, trustworthy, and reasonable in order to achieve rapid disease
treatment. It has been discovered that Machine Learning and Deep Learning may
help with decision-making and prediction-making using the vast amounts of data
that gathered from several healthcare firms. Machine learning methods and
approaches have been used to automate the study of big and complicated medical
information. Recently, some of the decorated researchers have employed various
machine learning to assist the healthcare sectors and professionals to identify
heart- related illness.
Before implementing the machine learning models, we need
authenticated medical records such as tabular data to predict the heart related
illnesses. Let’s look at the data in hand which is taken from the open-source
platform know as Kaggle, and this is the link to Heart Disease Dataset (kaggle.com). This data contains the following attributes.
 |
| Dataset Attributes |
Exploratory Data Analysis
What is Exploratory Data Analysis?
Exploratory Data Analysis (EDA) is an essential stage in the data analysis process that entails analyzing and graphically representing data sets to comprehend their primary attributes, reveal patterns, spot anomalies, and ascertain connections between variables. The main objective of Exploratory Data Analysis (EDA) is to get a deep understanding of the fundamental organization of the data, formulate hypotheses, and provide guidance for the later stages of analysis or modeling.
Let's open the CSV (Comma Separated Values) file, to get the Heart Disease Detection dataset. For the presented context, I will be using python programming language for code example.
1. Importing the important libraries for exploratory data analysis
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
2. Importing the dataset
df = pd.read_csv("/kaggle/input/heart-disease-dataset/heart.csv")
df.head() # viewing the first five rows of the dataset
Let's look at the shape of the dataset.
df.shape
From the shape of the dataset, we can observe that the dataset contains total 1025 data rows and 14 columns or attributes. Let's look at the data types of the different attributes of the data.
df.info()
Almost every attribute of the dataset has integer values except oldpeak is of float type. Let's look at the different properties of the dataset such as mean, min, standard deviation and more...
df.describe().T
3. Exploratory Data Analysis (EDA)
Let's look at the Gender distribution of the dataset. Where 1 - Male and 0 - Female.
df['sex'].value_counts()
In the given dataset there are total 713 male records and 312 female records. Let's create the bar chart for the same.
df['sex'].value_counts().plot(kind='bar', color=['orange', 'green'])
Let's look at the target values in the dataset. Where target: 1- Positive and 0 - Negative.
df['target'].value_counts()
In the dataset there are total 526 positive records and 499 negative records. Let's create the bar chart for the same.
df['target'].value_counts().plot(kind='bar', color=['red', 'green'])
Let's look at how many males and females in the records have heart diseases.
pd.crosstab(df.target, df.sex)
fig = sns.countplot(x = 'target', data = df, hue = 'sex')
fig.set_xticklabels(labels=["Doesn't have heart disease", 'Has heart disease'], rotation=0)
plt.legend(['Female', 'Male'])
plt.title("Heart Disease Frequency for Sex");
4. Checking the Correlation Within Dataset Attributes
x = df.corr()
plt.figure(figsize = (15,8))
sns.heatmap(x,annot = True)
From heatmap we can clearly observe that no column is shown significant contribution among all the attributes of the dataset. So, we are going to take all the features for the model evaluation. Let's look at the outliers among the dataset's attributes.
df.describe().T
The dataset columns `trestbps`, `chol`, `thalach` and `thal` shown some outliers among the datset.
5. Removing the Outliers from the Dataset
q1 = df['trestbps'].quantile(q = 0.25)
q3 = df["trestbps"].quantile(q = 0.75)
IQR = q3 - q1
IQR_lower_limit = int(q1 - (1.5*IQR))
IQR_upper_limit = int(q3 + (1.5*IQR))
print("Upper limit of IQR:",IQR_upper_limit)
print("Lower limit of IQR:",IQR_lower_limit)
cleaned_data = df[df["trestbps"]<IQR_upper_limit]
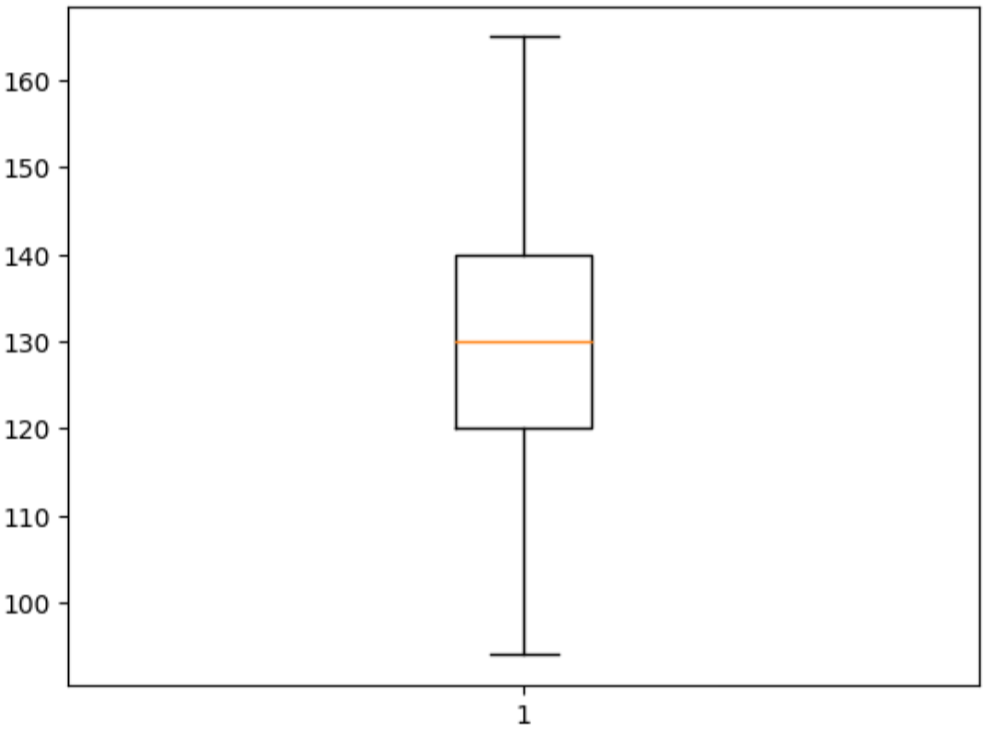
plt.boxplot(cleaned_data["trestbps"]) Now we can clearly see that there is no outlier in the dataset.
cleaned_data.shape
After removing the outliers there are only 980 records left in the dataset.
In this context we will employ the different methods of machine learning provided by the Scikit-Learn, to deploy such models that may help us predict the cardiovascular disease in timely manner to assist the healthcare system to aid the patient more effectively for more prompt recovery of patient. For this scenario we will implement machine learning models such as K-Nearest Neighbour (KNN), Logistic Regression (LR), and Random Forest (RF).
6. Building Model and Model Evaluation
6.1. One Hot-Encoding
cat_values = []
conti_values = []
for col in df.columns:
if len(df[col].unique()) >= 10:
conti_values.append(col)
else:
cat_values.append(col)
cat_values.remove('target')
cleaned_data = pd.get_dummies(cleaned_data, columns=cat_values)
6.2. Training and Testing Data Split
X = cleaned_data.drop(columns = 'target')
y = cleaned_data['target']
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=1)
6.3. Importing Sklearn Libraries for Building Model and Model Evaluation
from sklearn import metrics
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, mean_squared_error
from sklearn.metrics import accuracy_score
from math import sqrt
from sklearn.metrics import cohen_kappa_score
6.4. Logistic Regression
log_clf = LogisticRegression(max_iter=1000, penalty='l2', solver='liblinear', C=0.05, random_state = 4)
log_clf.fit(X_train, y_train)
log_score = metrics.f1_score(y_test, log_clf.predict(X_test))
log_score
Confusion Matrix for Logistic Regression Model # Making Prediction on the test set
y_preds = log_clf.predict(X_test)
print(classification_report(y_test, y_preds))
#Mean Square Error
train_preds = log_clf.predict(X_train)
mse = mean_squared_error(y_train, train_preds)
lrmse = sqrt(mse)
print("Error: ", lrmse)
fpr, tpr, thresholds = metrics.roc_curve(y_test, y_preds)
print(fpr)
print(tpr)
print(thresholds)
print("Cohen's Kappa Score: ", cohen_kappa_score(y_test, y_preds))
knn_clf = KNeighborsClassifier(algorithm='auto', leaf_size=45, n_neighbors=2, p=1)
knn_clf.fit(X_train, y_train)
knn_score = metrics.f1_score(y_test, knn_clf.predict(X_test))
knn_score
Confusion Matrix for K-Nearest Neighbor # Making Prediction on the test set
y_preds = knn_clf.predict(X_test)
print(classification_report(y_test, y_preds))
#Mean Square Error
train_preds = knn_clf.predict(X_train)
mse = mean_squared_error(y_train, train_preds)
knnrmse = sqrt(mse)
print("Error: ",knnrmse)
fpr, tpr, thresholds = metrics.roc_curve(y_test, y_preds)
print(fpr)
print(tpr)
print(thresholds)
print("Cohen's Kappa Score: ", cohen_kappa_score(y_test, y_preds))
rand_clf = RandomForestClassifier(n_estimators=100, random_state = 35)
rand_clf.fit(X_train, y_train)
ranf_score = metrics.f1_score(y_test, rand_clf.predict(X_test))
ranf_score
Confusion Matric for Random Forest # Making Prediction on the test set
y_preds = rand_clf.predict(X_test)
print(classification_report(y_test, y_preds))
#Mean Square Error
train_preds = rand_clf.predict(X_train)
mse = mean_squared_error(y_train, train_preds)
rfrmse = sqrt(mse)
print("Error: ",rfrmse)
fpr, tpr, thresholds = metrics.roc_curve(y_test, y_preds)
print("False Positive Rate: ",fpr)
print(tpr)
print(thresholds)
print("Cohen's Kappa Score: ", cohen_kappa_score(y_test, y_preds))
6.7. Model Accuracy Scores
# create a dictionary with all scores
score = [{'Model':'Logistic Regression', 'Score': log_score},
{'Model':'KNN', 'Score': knn_score},
{'Model':'Random Forest', 'Score': ranf_score}]
pd.DataFrame(score, columns=['Model','Score'])
The result of the proposed model demonstrates that the
Random Forest Model has the highest accuracy rating of 98.43%.
Please check out the complete python notebook code is available at Heart Disease Prediction KNN, LR and RF | Kaggle
This context is mere glimpse the work done in the Research paper Heart Disease Prediction Using Machine Learning Techniques | IEEE Conference Publication | IEEE Xplore . I hope you will like the content and Best of Luck for future expenditures!

















No comments:
Post a Comment